
































Вітаю всіх відвідувачів сайту info-comp.ru! сьогодні ми з вами поговоримо про те, як відбувається з’єднання таблиць в microsoft sql server на фізичному рівні, тобто за допомогою яких алгоритмів. Зокрема, ми розглянемо такі типи з’єднання як: nested loops, merge і hash match.
Введення
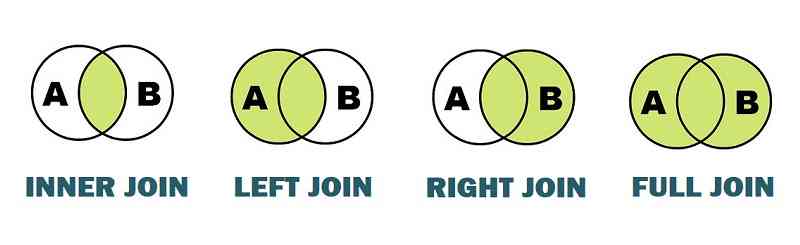
У мові t-sql існують наступні види з’єднання таблиць:
Види з’єднань в t-sql
Inner join – внутрішнє з’єднання
Left join – ліве зовнішнє з’єднання
Right join-праве зовнішнє з’єднання
Full join-повне зовнішнє з’єднання
Cross join – перехресне з’єднання
На фізичному рівні в microsoft sql server ці з’єднання реалізуються за допомогою спеціальних алгоритмів:
Який з цих алгоритмів застосувати до того чи іншого з’єднання, microsoft sql server визначає в процесі побудови плану виконання запиту, так як в залежності від умов кожен з цих алгоритмів може бути ефективніше інших. Іншими словами, в якихось умовах ефективніше буде nested loops, а в якихось merge або hash match.
У плані виконання запиту з’єднання таблиць позначається за допомогою наступних фізичних операторів, тобто якщо ви бачите ту чи іншу іконку, значить, дані були з’єднані за допомогою відповідного алгоритму
Які ще існують фізичні оператори і як вони позначаються в плані виконання запиту, ми розглядали в окремій статті.
Ну а зараз давайте детально розглянемо кожен тип фізичного з’єднання таблиць в microsoft sql server.
Типи фізичного з’єднання таблиць
Деякі можуть запитати: «а навіщо нам взагалі знати, як працює фізичне з’єднання таблиць в microsoft sql server?». Вся справа в тому, що якщо у вас досить багато завдань, пов’язаних з оптимізацією, то розуміння внутрішніх процесів, розуміння того, як працює той чи інший оператор в плані виконання запиту, допоможе вам у разі необхідності скорегувати запит і зробити його більш ефективним.
Крім цього, на співбесідах на позиції, які пов’язані з розробкою на t-sql, дуже часто люблять питати, як працює фізичне з’єднання таблиць, іншими словами, якщо ви йдете на позицію «t-sql розробник», то вас, напевно, в 95% випадках запитають про фізичне з’єднання таблиць nested loops, merge і hash match.
Тому знання і розуміння того, як фактично відбувається з’єднання даних в microsoft sql server, дуже корисно.
Додатково рекомендую почитати про архітектуру обробки запитів в microsoft sql server.
Nested loops join
nested loops 8 –&>- це оператор вкладених циклів, який відображає тип фізичного з’єднання даних.
Принцип роботи nested loops наступний: sql server для кожного значення одного набору даних (зазвичай, де менше записів), шукає відповідне значення в іншому наборі даних.
Іншими словами, sql server бере перше значення з першої таблиці (вона називається зовнішньої) і порівнює його послідовно з усіма значеннями в другій таблиці (вона називається внутрішньої), якщо знаходить відповідність, то запис включається в підсумковий набір даних. Коли значення з першого набору даних порівнялося з усіма знаменнями з другого набору, то береться друге значення першого набору і знову відбувається порівняння з усіма значеннями з другого набору і так відбувається до тих пір, поки кожне значення з першої таблиці, тобто. Зовнішньої, не буде порівняно з кожним значенням з другої таблиці, тобто внутрішньої.
Таким чином, у нас два цикли, зовнішній і внутрішній, звідси і назва – вкладені цикли.
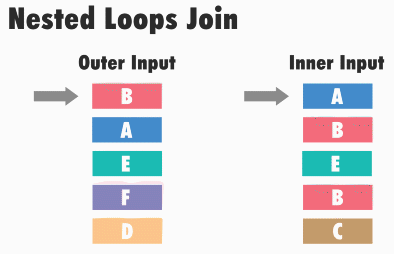
У такому вигляді nested loops працює не дуже ефективно, однак ефективність підвищується, якщо дані внутрішньої таблиці відсортовані по з’єднується стовпця, наприклад, якщо по ньому створений індекс.
Таким чином, кількість порівнянь зменшується за рахунок того, що значення відсортовані, а загальна швидкість роботи підвищується.
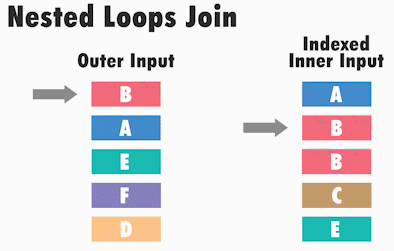

Тип фізичного з’єднання таблиць nested loops зазвичай виникає, коли ми з’єднуємо набори даних, де один з наборів має невеликий розмір, а інший набір даних порівняно великий і індексований по з’єднуються стовпцях. Nested loops зустрічається досить часто, так як є найшвидшою операцією з’єднання на невеликому обсязі даних.
примітка! якщо два набори даних мають досить великі розміри, то даний спосіб з’єднання буде вкрай неефективний.
Merge join
merge 8>–>- з’єднання злиттям.
Цей тип фізичного з’єднання даних є найшвидшим, однак, він вимагає, щоб обидва набори даних були відсортовані, наприклад, є індекси по з’єднуються стовпцях.
Merge найбільш ефективний в тих випадках, коли два набори даних досить великі, і як вже було зазначено, відсортовані по з’єднуються стовпцях.
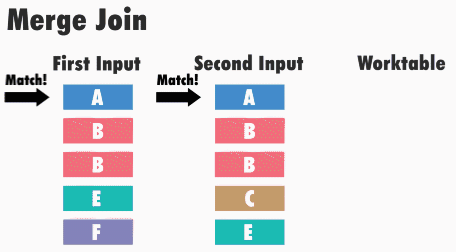
Принцип роботи даного типу з’єднання наступний: sql server отримує перші рядки з кожного набору вхідних даних і порівнює їх. Потім він продовжує порівняння наступних рядків з другого набору, до тих пір, поки значення відповідають значенню з першого набору даних. Як тільки значення більше не збігаються, sql server переходить до наступного рядка в наборі з меншим значенням і продовжує виконувати порівняння.
Наприклад, для операцій внутрішнього з’єднання рядки повертаються в тому випадку, якщо вони рівні. Якщо вони не рівні, рядок з меншим значенням не враховується, і з цього набору вхідних даних береться наступний рядок і знову відбувається порівняння. Цей процес повторюється, поки не буде виконана обробка всіх рядків, тобто поки цей, назвемо його, курсор, не дійде до кінця.
Даний алгоритм ефективний, тому що sql server не повинен повертатися і читати будь-які рядки кілька разів, тобто читання даних відбувається тільки один раз.
Однак алгоритм стає менш ефективним, коли в наборах існують повторювані значення, тобто коли відбувається з’єднання злиттям «багато до багатьох».
У таких випадках sql server записує будь-які повторювані значення з другої таблиці в тимчасову таблицю в базі даних tempdb і виконує порівняння там. Потім, якщо ці значення також дублюються в першій таблиці, sql server порівнює їх зі значеннями, які вже збережені в тимчасовій таблиці.
примітка! якщо обидва набори даних великі і мають подібні розміри, але не відсортовані, то з’єднання злиттям з попереднім сортуванням і хеш-з’єднання (hash match) мають приблизно однакову продуктивність. Однак хеш-з’єднання часто виконуються швидше, якщо набори даних значно відрізняються за розміром.
Hash match join
hash match – хеш-з’єднання.
Алгоритм з’єднання включає 2 фази:
- build
- probe
У першій фазі “build” будується хеш-таблиця за допомогою обчислення хеш-значення для кожного рядка одного набору даних (зазвичай меншого з двох). Ці хеші обчислюються на основі ключів з’єднання вхідних даних і потім зберігаються разом з рядком в хеш-таблиці.
Після побудови хеш-таблиці sql server починає фазу «probe». На цьому етапі він для кожного рядка іншого набору даних, за допомогою тієї ж хеш-функції, обчислює хеш-значення і здійснює пошук збігів по хеш-таблиці. Якщо він знаходить збіг для цього хешу, то потім він перевіряє, чи дійсно збігаються ключі з’єднання між рядком в хеш-таблиці і рядком з другої таблиці (йому необхідно виконати цю перевірку через потенційні хеш-колізій).
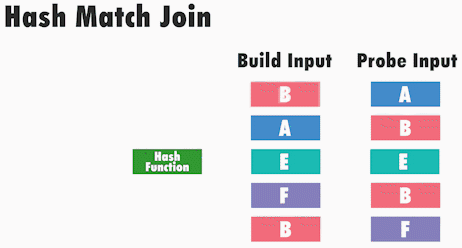
Варто відзначити, що іноді можуть виникати ситуації, коли на етапі «build» хеш-таблиця не може бути збережена повністю в пам’яті. У таких випадках sql server зберігає деяку частину даних в пам’яті, а іншу частину перенаправляє в tempdb.
Це відбувається, коли обсяг даних перевищує розмір, який може зберігатися в пам’яті, або коли sql server надає недостатній обсяг пам’яті, необхідний для з’єднання hash match.
Спосіб фізичного з’єднання даних hash match виникає, коли ми обробляємо великі, несортовані і неіндексовані набори даних, при цьому він робить це досить ефективно.
На сьогодні це все, сподіваюся, матеріал був вам корисний, поки!


















{kind=link}